Inteligência de dados com Databricks e Microsoft Fabric para os novos!
Este artigo é baseado em duas palestras que ocorreram no dia 19/11/2025 na Universidade de Vila Velha (UVV).
Uma meta que se renova todos os anos!

Voltar à Universidade de Vila Velha é mais do que um compromisso profissional — é uma meta pessoal que retorna a cada ano. No dia 19 de novembro de 2025, tive novamente essa oportunidade ao palestrar no evento TI 360 da UVV. Desta vez, abordei uma perspectiva amadurecida: como plataformas avançadas de dados estão se tornando surpreendentemente acessíveis, sem sacrificar poder e escala.
A conversa com Susiléa Abreu e toda a equipe reafirma por que apostamos em educação e compartilhamento. Não se trata apenas de "Databricks é bom" ou "Microsoft Fabric é poderoso" — a história é mais nuançada e interessante.
O paradoxo das plataformas modernas
Há alguns anos, montar uma infraestrutura de dados exigia grande esforço: integrar data warehouse, ETL, visualização e lakehouse. Cada peça trazia complexidades, licenças e equipes especializadas, resultando em centralização excessiva no BI.
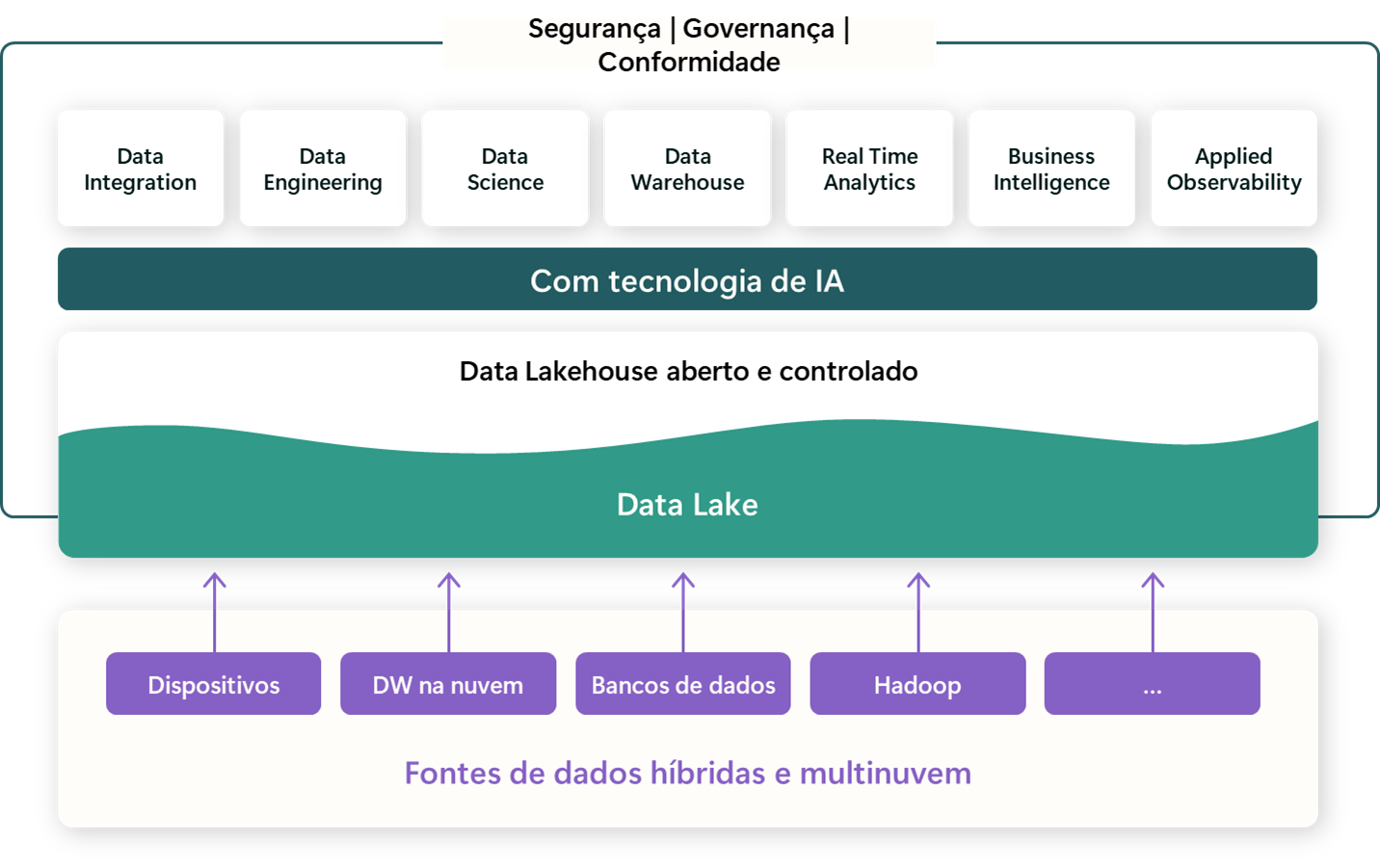
Hoje, o paradoxo é fascinante: Microsoft Fabric e Databricks são simples para casos iniciais, mas lidam com petabytes, tempo real e ML em produção.
Ambas foram projetadas para progressão natural: comece simples e escale, com todos os recursos na mesma solução conforme a maturidade avança.
Databricks: Plataforma Unificada Centrada em Dados
Sem dúvida, o Databricks dividiu águas com o Lakehouse, convergindo data warehouse (controle transacional) e data lake (flexibilidade e custo baixo).
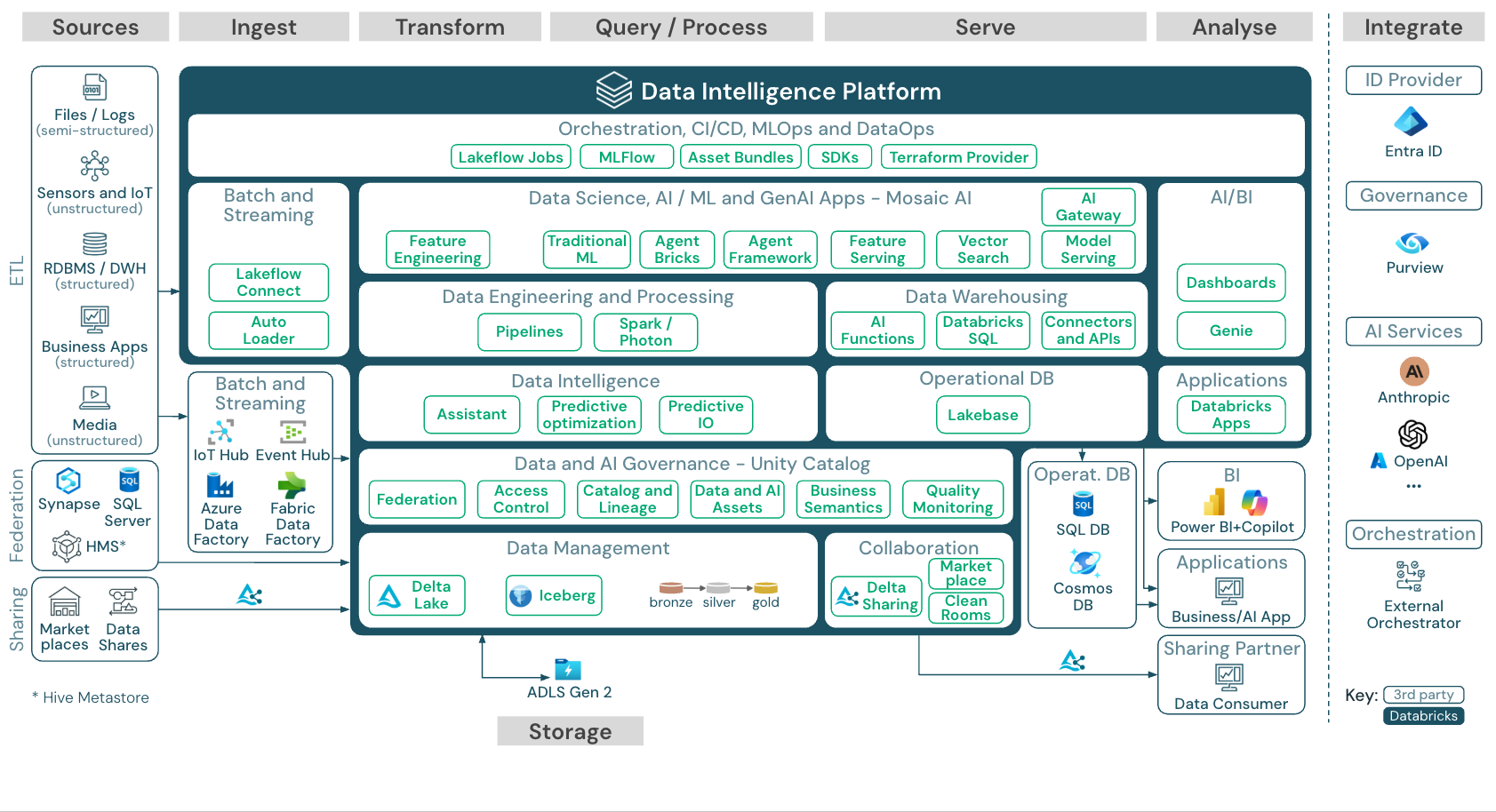
Em um mundo serverless, destaca-se por:

- Delta Lake como storage (Parquet com ACID transactions)
- Compute separado do storage (pague só pelo uso)
- SQL Warehouses (BI rápido), All-Purpose Clusters (ETL), Jobs Clusters (automação)
- Feature Store, MLflow (ciclo de ML), Vector Search (GenAI)
- Query Federation (consulte Snowflake, BigQuery etc. sem replicar)
- Multi-cloud (AWS, Azure, GCP) com formatos abertos
Para escala:
- Medallion Architecture (Bronze/Silver/Gold)
- Unity Catalog (UC) com suporte a Apache Iceberg (Public Preview 2025), ABAC (Beta para acesso dinâmico via tags) e Metrics para governança
- Workflows com retry, alertas e linhagem
- Streaming via Structured Streaming
Um analista inicia com SQL/Python em notebooks; empresas escalam sem fricção.
Microsoft Fabric: Arquitetura Unificada
O Fabric resolve silos de ferramentas com um all-in-one no mesmo SKU: cresça só em infraestrutura, otimizando com Spark e revisões.
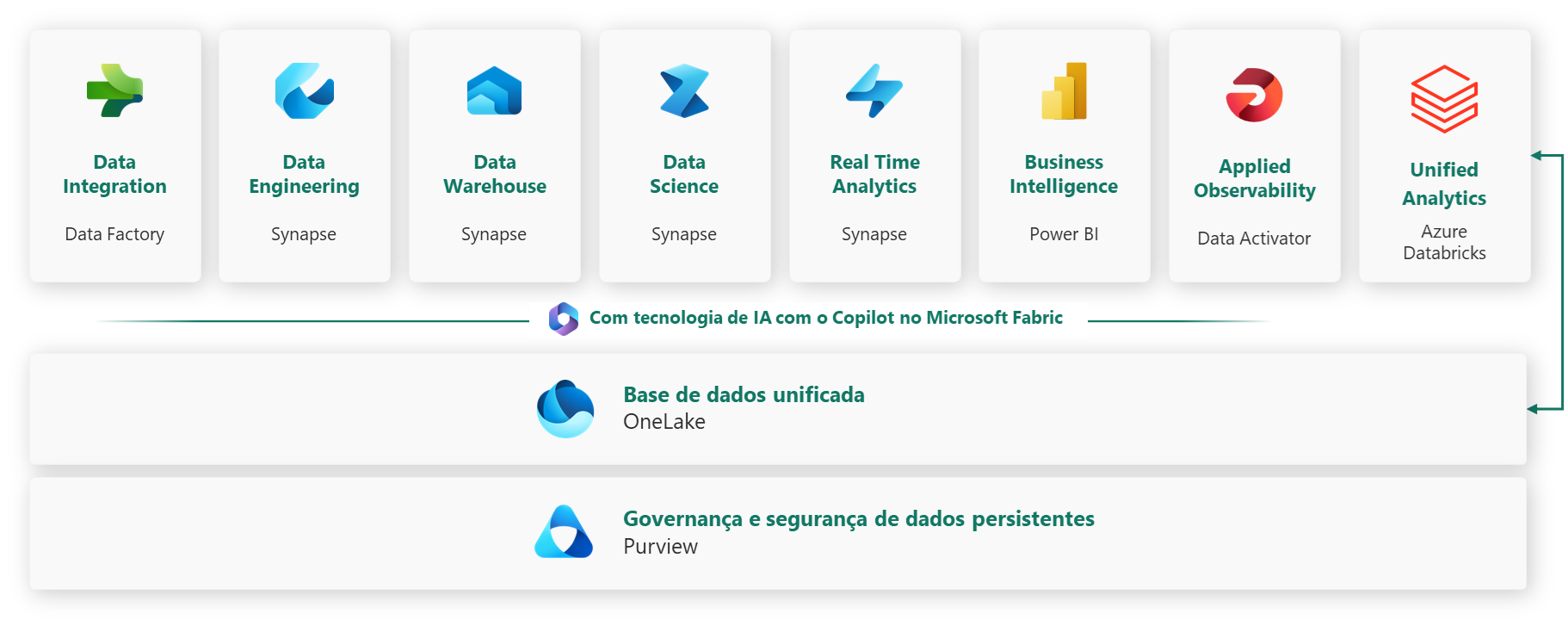
Ao habilitar Fabric:
- Data Factory (orquestração)
- Data Engineering (Spark notebooks/jobs)
- Data Warehouse (analíticas)
- Real-Time Analytics (KQL)
- Power BI integrado
- Data Science (Python, R, Azure ML)
- OneLake elimina duplicações, com suporte a Iceberg tables (virtualização Delta/Iceberg para interoperabilidade) e segurança unificada.
Convergência das Plataformas
"Qual escolher?" Depende. Veja a comparação:
| Critério | Microsoft Fabric | Databricks |
|---|---|---|
| Ecossistema | Microsoft (Power BI, M365) | Multi-cloud (AWS, Azure, GCP) |
| ML/IA Foco | AI Functions, Copilot (GA 2025) | MLflow, Vector Search, Feature Store |
| Licenciamento | Capacidade fixa | Pay-per-use, spot instances |
| Governança | OneLake com Iceberg/Delta | Unity Catalog com Iceberg/ABAC |
| Visualização | Power BI nativo | Integra Power BI/Tableau/Looker |
Insight da UVV: Ambas convergem em Spark, Delta Lake/Iceberg (ACID, time travel). Não assusta mais processar bilhões — mindset é a barreira nas empresas. Analistas sênior ingerem, processam, aplicam ML e visualizam com poucas linhas ou UI.
Agradecimento Final
 Obrigado a Susiléa Abreu, equipe UVV e participantes do TI 360 em 19/11/2025. Essa iniciativa reflete minhas contribuições em 2025 para democratizar dados no ES, Brasil e mundo!
Obrigado a Susiléa Abreu, equipe UVV e participantes do TI 360 em 19/11/2025. Essa iniciativa reflete minhas contribuições em 2025 para democratizar dados no ES, Brasil e mundo!
Comente ou conecte no LinkedIn!
Referências
Plataformas:
Arquitetura:
ML/IA: