Num cenário de multiplicidade normativa, a LGPD (lei n. 13.709 de 2018) reuniu conceitos e princípios básicos da gestão de dados pessoais, o que facilita a adequação das empresas e conscientização das pessoas sobre seus direitos. O domínio dos conceitos e dos princípios contidos na LGPD não cabe apenas aos setores jurídicos das empresas. As equipes de tecnologia também devem conhecê-los, ainda que superficialmente, de modo a mitigar riscos, agilizar o trabalho e gerar valor para a empresa. Logo, vamos explorar um dos pontos essenciais da LGPD: os tipos de dados.
A LGPD conceitua dado pessoal como sendo a informação relacionada a pessoa natural identificada ou identificável (artigo 5º, inciso I). O que torna possível qualificar determinado dado como pessoal, atraindo a regulação da LGPD? Ao redor do mundo, as leis que protegem os dados pessoais adotam uma de duas estratégias para essa qualificação: a expansionista ou a reducionista.
A estratégia reducionista submete uma menor quantidade de dados ao escopo da lei de proteção. Consideram-se dados pessoais somente aquelas informações diretamente relacionadas a uma pessoa natural identificada. Essa abordagem exige que o dado esteja vinculado direta, precisa, imediata e exatamente a uma pessoa específica, não havendo dúvidas quanto à titularidade. São exemplos de dados pessoais, para a estratégia reducionista, o RG, o CPF e a biometria. Contudo, a nossa lei de proteção adotou a estratégia expansionista ao definir dado pessoal como a informação relacionada a uma pessoa natural identificada ou identificável. Assim, uma quantidade maior de dados pode ser qualificada como pessoal, por exemplo, a profissão, os interesses pessoais, o endereço de IP e o e-mail corporativo.
Então, no Brasil, aquela informação que possa, ou que tem o potencial de, tornar a pessoa identificável também está protegida. Edson Pires da Fonseca apresenta o seguinte exemplo: "A cor azul de uma camisa, por exemplo, em um estádio de futebol no qual a cor do time da casa é azul, não representa um dado pessoal, pois não é suficiente para identificar o titular; contudo, dentro de um banco de dados específico, como uma sala de aula, na qual apenas Joana veste camisa azul, a cor da camisa será um dado pessoal, pois pode identificar uma pessoa natural".
E quais são as repercussões práticas da adoção de uma ou de outra estratégia? A abordagem expansionista adquire relevância a partir do momento em que os negócios passam a incorporar tecnologias que redimensionam a forma como produzimos, agregamos, analisamos e extraímos valor de grandes conjuntos de informação, como Big Data, Machine Learning e Inteligência Artificial.
Um dado isolado pode não ter muito valor, mas várias informações reunidas podem formar um mosaico que vai nos levar a uma pessoa específica. Em 2016, por exemplo, pesquisadores britânicos utilizaram técnicas de perfilamento geográfico para tentar identificar o artista anônimo conhecido como Banksy. Todas as informações utilizadas na pesquisa não têm nome e nem rosto, não estando relacionadas a uma pessoa identificada. No entanto, uma vez agregadas, combinadas, ordenadas e analisadas, elas podem tornar uma pessoa identificável.
Para determinar se um dado é pessoal, devemos, ainda, fazer uma análise do contexto em que o dado está sendo tratado. Em 2016, a Corte Europeia de Justiça entendeu que um número de IP era dado pessoal, porque, sendo tratado por um provedor de conexão em conjunto com outras informações, permitia a identificação de uma pessoa.
Então, ao tratar um dado, devemos nos perguntar: esse dado, se agregado a outros que tenho, tornam determinada pessoa identificável? Se sim, estamos lidando com um dado pessoal.
O dado pessoal sensível representa uma proteção adicional da intimidade. De acordo com o artigo 5º, inciso II, da LGPD, o dado pessoal sensível é o "dado pessoal sobre origem racial ou étnica, convicção religiosa, opinião política, filiação a sindicato ou a organização de caráter religioso, filosófico ou político, dado referente à saúde ou à vida sexual, dado genético ou biométrico, quando vinculado a uma pessoa natural". Inicialmente, nenhuma empresa ou indivíduo pode fazer uso desse tipo de informação, porém há situações legais que permitem exceções (artigo 11 da LGPD).
Qual é o oposto de um dado pessoal? Um dado anônimo. A LGPD conceitua dado anonimizado como aquele relativo a titular que não possa ser identificado, considerando a utilização de meios técnicos razoáveis e disponíveis na ocasião do seu tratamento (artigo 5º, inciso III). De acordo com Bruno Ricardo Bioni, dados anônimos podem ser entendidos como dados que não são capazes de revelar a identidade de uma pessoa após passarem por um processo de quebra do vínculo entre o dado e o seu titular.
Bruno Ricardo Bioni ainda fala que, teoricamente, essa definição é perfeita, mas, tecnologicamente, ela é problemática, sobretudo num contexto de crescente avanço das tecnologias que processam dados. Não existe, hoje, uma divisória evidente e rígida entre dados pessoais e dados anonimizados. Aliás, encontramos estudos que evidenciam como reverter o processo de anonimização pode ser mais simples do que se imagina. Arvind Narayanan, professor de Ciência da Computação em Princeton, demonstrou como a reversão da anonimização foi possível por meio do uso de outro dado de 33 bits.
A LGPD define o que é anonimização como “utilização de meios técnicos razoáveis e disponíveis no momento do tratamento, por meio dos quais um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo” (artigo 5º, inciso XI). A anonimização é um processo que conta com várias técnicas, como, por exemplo, supressão, generalização, randomização e pseudoanonimização. Por meio dessas técnicas, o dado deixa de ser pessoal ou sensível e passa a ser anônimo.
Um CPF pode ser suprimido para não constar numa base de dados. Um nome pode ser generalizado para conter apenas o prenome (primeiro nome), o que ainda possibilitaria a personalização em e-mail marketing. Um CEP pode ser generalizado com a disponibilização apenas dos 5 primeiros números. Uma idade pode ser generalizada para ser enquadrada numa faixa etária, de modo a evitar a individualização. Essas simples medidas são o suficiente para garantir segurança aos titulares dos dados e às entidades que estão tratando os dados.
Alguns parágrafos acima, destacamos que a LGPD, ao conceituar dado anonimizado, fala em “utilização de meios técnicos razoáveis e disponíveis na ocasião do seu tratamento”. O artigo 12 da LGPD prescreve que “dados anonimizados não serão considerados dados pessoais para os fins desta Lei, salvo quando o processo de anonimização ao qual foram submetidos for revertido, utilizando exclusivamente meios próprios, ou quando, com esforços razoáveis, puder ser revertido”.
Portanto, podemos entender que, se for necessário empregar um esforço fora do razoável para associar um dado anonimizado a uma pessoa, esse dado não será considerado um dado pessoal. Mas o que seriam, efetivamente, esforços razoáveis? Esta noção, em si, é bastante ampla, e foi por esta razão que a lei previu alguns parâmetros objetivos para a compreensão do que seriam esforços razoáveis: 1) custo, 2) tempo; e 3) estado da arte.
Se a reversão de determinado processo de anonimização demandar altos custos financeiros, isso foge da ideia de um esforço razoável. Igualmente, se for necessário empregar um grande conjunto de computadores e processadores para tratar, descriptografar, cruzar aquelas informações por um período de um ano ou dois anos, será que isso está no escopo de um esforço razoável? Evidentemente que não.
Por fim, deve-se analisar o estado da arte das tecnologias disponíveis para a reversão de determinado processo. Talvez, em 2 anos, a depender dos avanços da computação, alguns esforços que hoje são irrazoáveis passem a ser bastante factíveis.
Essa noção de razoabilidade, portanto, é circunstancial, dependendo do estágio de desenvolvimento no qual se encontra a tecnologia.
A pseudoanonimização substitui o valor original do dado por um outro valor, mantendo uma relação com o valor original, a fim de possibilitar a reversão com token ou hash. Ao contrário da utilização de dados anonimizados, o que afasta a aplicação direta da LGPD, não há previsão legal específica para os dados pseudonimizados. Ainda assim, é possível imaginar vantagens na sua utilização pelas empresas.
De um ponto de vista da segurança da informação, a pseudonimização garante mais segurança ao tratamento dos dados, podendo mitigar os danos causados por eventuais vazamentos, especialmente se os dados afetados forem somente aqueles não identificáveis.
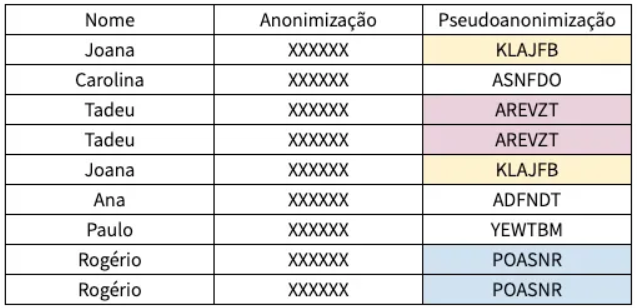
O quadro abaixo, elaborado por Jessica Sombrio, exemplifica a distinção entre anonimização e pseudoanonimização. Nas palavras da autora, “(…) aplicando a pseudoanonimização os nomes originais dos compradores são escondidos, porém, é possível realizar uma relação entre eles, pois os mesmos valores originais terão os mesmos pseudônimos, portanto apesar de você não saber quem é KLAJFB, você sabe que esse cliente realizou duas compras no mesmo dia”.
Após a classificação dos dados com quais estamos lidando, podemos começar a tratá-los da melhor maneira possível. Logo, podemos dizer que essa é a etapa essencial para o adequado tratamento dos dados. Para isso, precisamos ter em mente os princípios que norteiam e legitimam o tratamento de dados pessoais (artigo 6º da LGPD) e as bases legais para o tratamento de dados pessoais (artigo 7º da LGPD). Ademais, precisamos ter rígidos mecanismos de controle e segurança da informação de ponta a ponta, desde o consentimento do usuário até o destino final do dado.
Agende uma reunião com a Datasource Expert e prepare-se para o futuro estando em conformidade com a LGPD: Clique aqui para agendar.
BIONI, Bruno Ricardo. Compreendendo o conceito de anonimização e dado anonimizado. Disponível em: https://aplicacao.aasp.org.br/aasp/servicos/revista_advogado/paginaveis/144/20/index.html. Acesso em: 15 de janeiro de 2023.
FAHEL, Ariel. A LGPD entrou em vigor! E agora? — Uma breve introdução ao tema. Disponível em: https://blog.dp6.com.br/a-lgpd-entrou-em-vigor-e-agora-uma-breve-introdu%C3%A7%C3%A3o-ao-tema-facec764d33b. Acesso em: 18 de janeiro de 2023.
FONSECA, Edson Pires. Lei geral de proteção de dados pessoais - LGPD. 2 ed. Editora JusPODIVM. 2022.
HAUGE et al. Tagging Banksy: using geographic profiling to investigate a modern art mystery. Taylor & Francis, 2016. Link: https://core.ac.uk/download/pdf/77040608.pdf
Banksy unmasked? Scientists use maths and criminology to map artist’s identity. The Guardian, 05 mar. 2016. Disponível em: https://www.theguardian.com/artanddesign/2016/mar/05/banksy-unmasked-scientists-use-maths-and-criminology-to-map-artists-identity. Acesso em: 15 de janeiro de 2023.
KELLEHER, Denis. In Breyer decision today, Europe’s highest court rules on definition of personal data. Disponível em: https://iapp.org/news/a/in-breyer-decision-today-europes-highest-court-rules-on-definition-of-personal-data/. Acesso em: 17 de janeiro de 2023.
NARAYANAN, Arvind. One more re-identification demonstration, and then I’m out. Disponível em: https://33bits.wordpress.com/. Acesso em 17 de janeiro de 2023.
NETO, Joaquim. Segurança da informação e proteção de dados — Parte 1. Disponível em: https://blog.dp6.com.br/seguran%C3%A7a-da-informa%C3%A7%C3%A3o-e-prote%C3%A7%C3%A3o-de-dados-parte-1-3e87be468b56. Acesso em: 17 de janeiro de 2023.
RIBEIRO, Lucas. Boas práticas do uso do consentimento na LGPD. Disponível em: https://medium.com/dp6-blog/boas-pr%C3%A1ticas-do-uso-do-consentimento-na-lgpd-71c07e21ae01. Acesso em 17 de janeiro de 2023.
SOMBRIO, Jessica. Anonimização ou Pseudoanonimização? Qual a diferença? Disponível em: https://kondado.com.br/blog/blog/2020/10/13/anonimizacao-ou-pseudoanonimizacao-qual-a-diferenca/. Acesso em 17 de janeiro de 2023.