Databricks Metric Views - A Resposta para a camada OLAP que faltava
O dilema da plataforma completa
Há muito tempo o Databricks se posiciona como a plataforma completa de inteligência de dados e IA. E realmente é! Com suas capacidades de engenharia de dados, analytics, machine learning e agora GenAI integradas, ela é praticamente um ecossistema all in one, mas havia uma lacuna persistente que nos fazia questionar essa completude: onde estava a camada OLAP nativa? É o que podemos chamar de calcanhar de Aquiles.
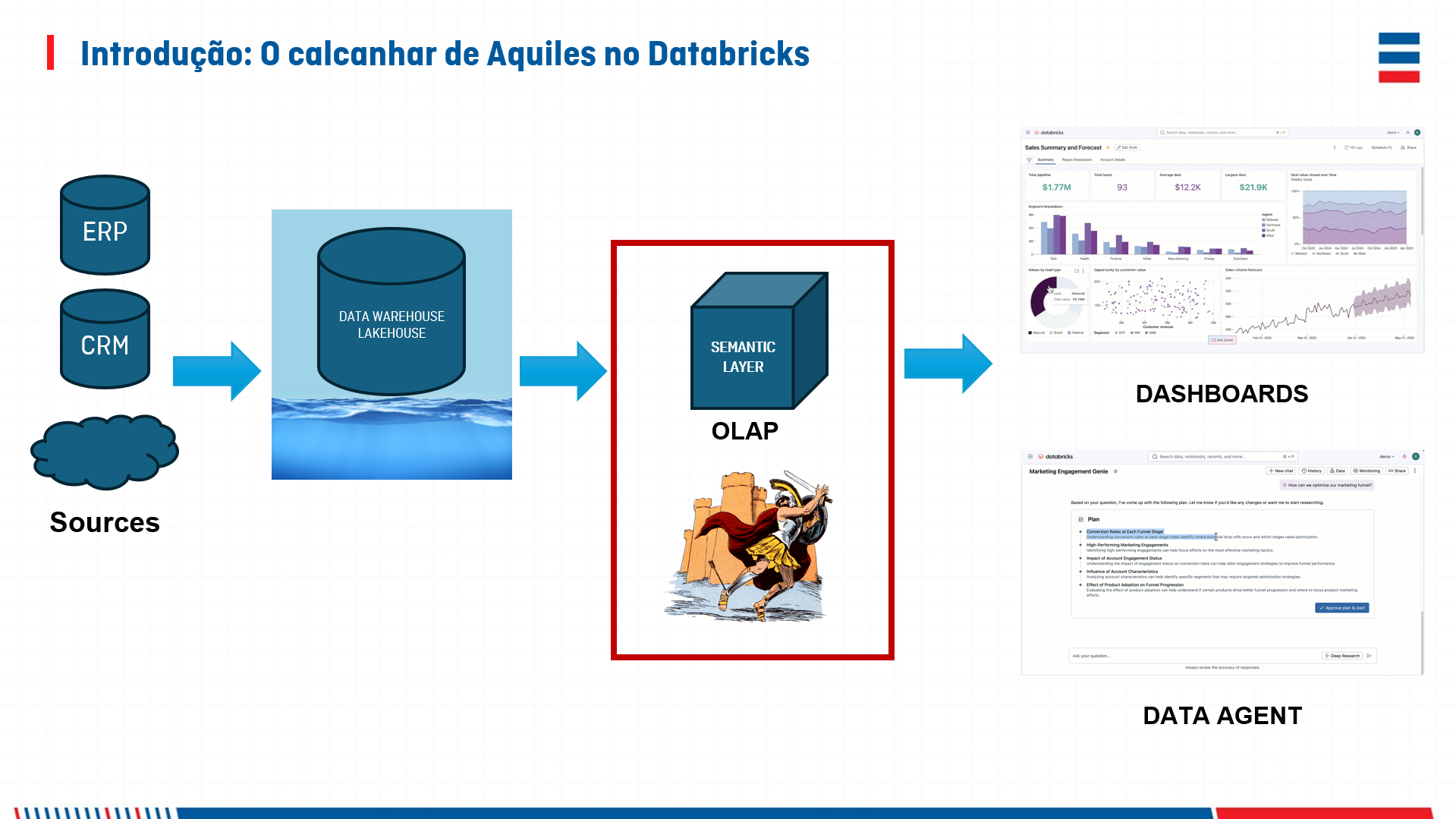
Durante anos, essa foi a resposta: "Use Databricks para armazenamento, engenharia de dados e machine learning, mas depois conecte o Power BI ou outra ferramenta de visualização para a camada semântica."
Funcionava, claro, mas deixava um incômodo constante, principalmente se falarmos de Power BI onde você ficaria limitado a conexões por importação ou DirectQuery. E por que isso não era bom?
- Duplicação de lógica: regras de negócio definidas em duas plataformas
- Complexidade operacional: duas plataformas para gerenciar, manter e evoluir
- Custo: licenças adicionais de BI e a overhead de sincronização de dados
- Latência: os dados não estavam "vivos" na mesma plataforma onde eram transformados
E então chegaram as Metric Views. Tema sobre o qual palestrei recentemente no evento Data & AI Saturday - Vitória - 2025, clique aqui e confira como foi.

O que são Metric Views?
Metric Views são uma camada semântica nativa do Databricks que permite definir métricas, dimensões e relacionamentos diretamente no lakehouse. Em essência, elas implementam a funcionalidade OLAP que faltava — aquela capacidade de fazer slicing, dicing e agregações multidimensionais sem sair da plataforma.
Antes das Metric Views, a arquitetura típica era:
graph LR
Source1(ERP) -->| Batch | Bronze1(Bronze: ERP) --> Silver(Silver)
Source2(CRM) -->| Batch | Bronze2(Bronze: CRM) --> Silver(Silver)
Source3(IoT) -->| Streaming | Bronze3(Bronze: Teletrias) --> Silver(Silver)
Silver(Silver) -->| Import ou DirectQuery
| PowerBI(Camada Semântica) -->| LiveConnection | Dashboards(Dashboards)
PowerBI(Camada Semântica) -->| LiveConnection | Reports(Reports)
leg1[Fontes de dados] -->| Ingestão
| leg2[Databricks] --> | Transformações
| leg3[Databricks] --> | Conexão
| leg4[Power BI] --> | Conexão
| leg5[Power BI]Agora, com Metric Views, você tem:
graph LR
Source1(ERP) -->| Batch | Bronze1(Bronze: ERP) --> Silver(Silver)
Source2(CRM) -->| Batch | Bronze2(Bronze: CRM) --> Silver(Silver)
Source3(IoT) -->| Streaming | Bronze3(Bronze: Teletrias) --> Silver(Silver)
Silver(Silver) --> PowerBI(Camada Semântica) --> Dashboards(Dashboards)
leg1[Fontes de dados] -->| Ingestão
| leg2[Databricks] --> | Transformações
| leg3[Databricks] --> | Conexão
| leg4[Databricks] --> | Conexão
| leg5[Databricks]Tudo integrado. Tudo no mesmo lugar. Tudo vivo.
Por que isso importa tanto?
 Deixa eu ser direto: essa é uma das mudanças mais significativas da evolução recente do Databricks. Aqui está o porquê:
Deixa eu ser direto: essa é uma das mudanças mais significativas da evolução recente do Databricks. Aqui está o porquê:
1. Camada Semântica centralizada
Você define uma métrica uma única vez. Todos os dashboards, relatórios e análises usam a mesma definição. Não há mais "qual é o número de receita certo?" porque há apenas uma fonte da verdade.
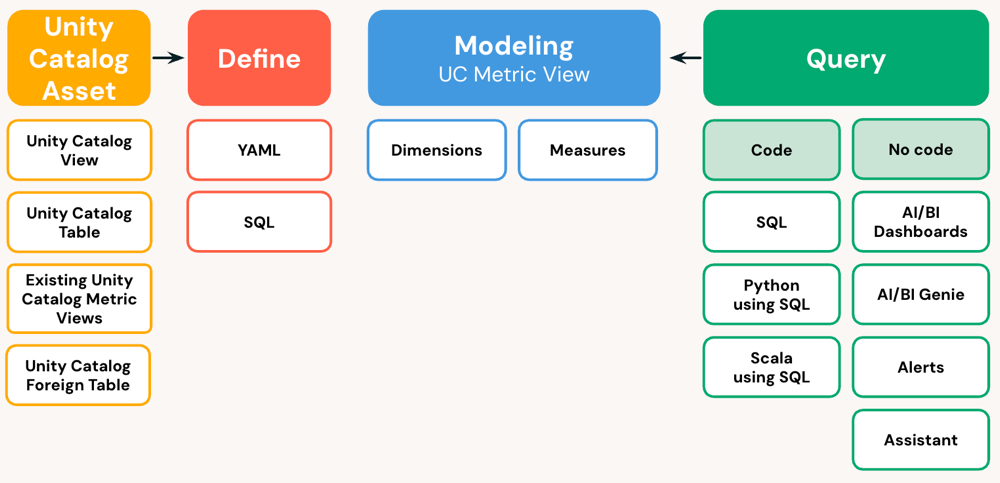
Com a definição da metric view, podemos estabelecer quais campos podem ser utilizados como dimensão e quais como medidas.
2. Inteligência próxima aos dados
Sua lógica de negócio vive onde seus dados vivem. Não há importação de dados, sincronização externa ou atrasos. A métrica é calculada sob demanda, sempre fresca, sempre consistente.
3. Redução de dependências externas
Você não precisa mais de Power BI ou Tableau como camada obrigatória para BI semântico. Claro, você ainda pode usá-los se desejar — eles se integram perfeitamente — mas agora é uma escolha, não uma necessidade.
4. Governança unificada
Controle de acesso, auditoria, linhagem de dados — tudo acontece em um único lugar. Não há mais descobrir "de onde vieram esses números?" porque a rastreabilidade é automática.
Como funciona na prática?
Criar uma Metric View é surpreendentemente direto: feito através de sintaxe SQL como uma view, porém com uma estrutura interna definida em YAML. Veja o exemplo:
%sql
CREATE OR REPLACE VIEW seucatalogo.tpch_orders.mv_orders
WITH METRICS
LANGUAGE YAML
AS $$
version: 1.1
source: samples.tpch.orders
comment: Comprehensive sales metrics with enhanced semantic metadata
dimensions:
- name: order_date
expr: o_orderdate
comment: Date when the order was placed
display_name: Order Date
format:
type: date
date_format: year_month_day
leading_zeros: true
synonyms:
- order time
- date of order
- name: customer_segment
expr: |
CASE
WHEN o_totalprice > 100000 THEN 'Enterprise'
WHEN o_totalprice > 10000 THEN 'Mid-market'
ELSE 'SMB'
END
comment: Customer classification based on order value
display_name: Customer Segment
synonyms:
- segment
- customer tier
measures:
- name: total_revenue
expr: SUM(o_totalprice)
comment: Total revenue from all orders
display_name: Total Revenue
format:
type: currency
currency_code: USD
decimal_places:
type: exact
places: 2
hide_group_separator: false
abbreviation: compact
synonyms:
- revenue
- total sales
- sales amount
- name: order_count
expr: COUNT(1)
comment: Total number of orders
display_name: Order Count
format:
type: number
decimal_places:
type: all
hide_group_separator: true
synonyms:
- count
- number of orders
- name: avg_order_value
expr: SUM(o_totalprice) / COUNT(1)
comment: Average revenue per order
display_name: Average Order Value
format:
type: currency
currency_code: USD
decimal_places:
type: exact
places: 2
synonyms:
- aov
- average revenue
$$
No caso acima, a view foi construída sobre a tabela samples.tpch.orders e define, de forma clara e reutilizável, as principais dimensões e medidas para análise de vendas:
Dimensões
- Order Date: Representa a data em que o pedido foi realizado, formatada de maneira padronizada para facilitar análises temporais.
- Customer Segment: Classifica automaticamente cada pedido em segmentos de cliente (Enterprise, Mid-market ou SMB) com base no valor total do pedido, permitindo análises segmentadas sem necessidade de cálculos adicionais.
Medidas
- Total Revenue: Soma o valor total de todos os pedidos, fornecendo uma visão consolidada da receita.
- Order Count: Conta o número total de pedidos, essencial para acompanhar o volume de vendas.
- Average Order Value: Calcula o ticket médio, ou seja, a média de valor por pedido, um indicador fundamental para entender o comportamento de compra dos clientes.
Mas isso é apenas a superfície. A verdadeira magia vem quando você:
- Define relacionamentos entre tabelas (fatos e dimensões):
- Especifica agregações e seus comportamentos padrão
- Implementa regras de negócio na semântica (cálculos derivados)
- Controla acesso granular aos dados
A seguir, vemos a metric view com outras cláusulas, adicionando contextos de junção, filtro e definição de medidas como semi-aditivas (algo bem interessante):
%sql
CREATE OR REPLACE VIEW seucatalogo.tpch_orders.mv_orderslines
WITH METRICS
LANGUAGE YAML
AS $$
version: 1.1
source: samples.tpch.lineitem
joins:
- name: orders
source: samples.tpch.orders
"on": l_orderkey = orders.o_orderkey
joins:
- name: customer
source: samples.tpch.customer
"on": orders.o_custkey = c_custkey
filter: "l_shipdate >= '1995-01-01' AND orders.o_orderstatus IN ('O', 'F')"
comment: "Metric view for analyzing open and fulfilled line items, orders, and customer data since 1995 in TPCH. Joins orders and customer via a snowflake schema."
dimensions:
- name: ship_date
expr: l_shipdate
comment: Date the item was shipped
display_name: Ship Date
format:
type: date
date_format: year_month_day
leading_zeros: false
synonyms:
- shipment date
- date shipped
- name: customer_nation
expr: orders.customer.c_nationkey
comment: Nation key for the customer
display_name: Customer Nation Key
synonyms:
- nation key
- customer nation
measures:
- name: total_quantity
expr: SUM(l_quantity)
comment: Total quantity shipped
display_name: Total Quantity
format:
type: number
decimal_places:
type: exact
places: 2
abbreviation: compact
synonyms:
- quantity sum
- total qty
- name: total_revenue
expr: SUM(l_extendedprice * (1 - l_discount))
comment: Total revenue from shipped items
display_name: Total Revenue
format:
type: currency
currency_code: USD
decimal_places:
type: exact
places: 2
abbreviation: compact
synonyms:
- revenue
- gross revenue
- name: trailing_30d_quantity
expr: MEASURE(total_quantity)
window:
- order: ship_date
semiadditive: last
range: trailing 30 day
comment: Quantity shipped in the trailing 30 days
display_name: Trailing 30 Day Quantity
format:
type: number
decimal_places:
type: exact
places: 2
abbreviation: compact
synonyms:
- 30d quantity
- rolling quantity
$$
Benefícios desta abordagem
- Consistência: As definições das métricas ficam centralizadas e documentadas, evitando divergências entre relatórios.
- Reutilização: Qualquer analista pode consumir essas métricas via SQL, sem precisar conhecer a estrutura física dos dados.
- Governança: O uso do Unity Catalog garante rastreabilidade e controle de acesso sobre as métricas e os dados subjacentes.
A Databricks publicou recentemente um ótimo artigo sobre "Databricks Lakehouse Data Modeling: Myths, Truths, and Best Practices" que aborda exatamente isso.
Impacto nos dashboards
Isso não é só bom para governança — é transformador para o desenvolvimento de dashboards. Os Dashboards do Databricks ganham acesso a:
- Métricas pré-calculadas com semântica consistente
- Drill-down inteligente através de dimensões
- Performance otimizada: as agregações são cacheadas e otimizadas; além disso, as metric views podem gerenciar toda a materialização dos dados envolvidos, se necessário
- Colaboração nativa (construa ao lado de seus dados)
Agora você pode oferecer aos seus usuários de negócio a mesma experiência "OLAP clássica" (cubes, pivots, drill-through) que tinham em ferramentas caras, mas dentro do Databricks, mais barato e mais flexível.
O início de uma nova era
Este é o momento em que dizemos: você não precisa mais de uma ferramenta BI externa como requisito tecnológico para ter um data lakehouse de qualidade. Você pode, se quiser — Power BI integra-se lindamente — mas agora é opcional, não obrigatório. Isso muda o jogo.
Assistir à evolução do Databricks nestes últimos anos foi fascinante. Passamos de "é ótimo para engenharia, mas você precisa de outra coisa para BI" para "é uma plataforma completa, de verdade." Metric Views é a prova de que essa evolução é contínua.
A pergunta que nos colocávamos há anos — "E a camada OLAP?" — finalmente tem uma resposta satisfatória. E a resposta está, apropriadamente, dentro da plataforma.
Referências e Aprofundamento: